
This post is part of a series that compares Ardor to other blockchain projects with similar features or goals. You can find the previous posts here:
- Ardor vs. Plasma
- Ardor vs. the Competition, Pt. 1: Lisk
- Ardor vs. the Competition, Pt. 2: NEM/Mijin/Catapult
- Ardor vs. the Competition, Pt. 3: IOTA
- Ardor vs. the Competition, Pt. 4: Waves
- Ardor vs. the Competition, Pt. 5: Stratis
- Ardor vs. the Competition, Pt. 6: Komodo/SuperNET
- Ardor vs. the Competition, Pt. 7: Ethereum (Smart Contracts)
This article continues the previous installment’s comparison between Ardor and Ethereum. This time, I explore how each platform approaches the problem of blockchain bloat. To my surprise, the two platforms are more similar in this regard than I had initially thought, though there are certainly significant differences, too.
Key to this comparison is an understanding of how the Ethereum blockchain is organized.
Ethereum’s Structure
Like Nxt, Ethereum tracks the current state of all accounts with each new block. And like Bitcoin, Ethereum organizes the information in each block into a Merkle tree (actually, three of them) and stores its root hash in the block’s header.
How exactly does this work? The diagrams from this article help to illustrate.
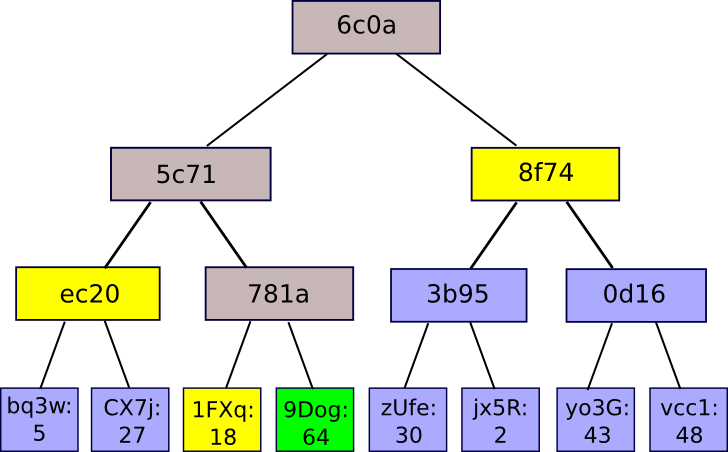
The leaf nodes of a Merkle tree (i.e., those at the bottom) represent all of the actual data stored in it. Each node above the leaves stores a cryptographic hash of its two children. (Note that I’m using “node” here to refer to items in the tree, not computers on the network. Each computer on the network stores the entire tree.)
This design has the property that if even a single leaf node changes by a single byte, the hash of its parent changes as well, along with the hash of its parent’s parent, and so on all the way up to the topmost node, called the “Merkle root.” In a sense, the Merkle root contains a digest of all of the information in the leaf nodes.
Simply grouping all of the leaf nodes together and hashing them all at once would produce a similar result, but the tree structure has a second nice property, which is that it is possible to prove that a single leaf is in the tree without seeing the entire tree. For example, in this diagram it is possible to prove that the green transaction has been included by supplying its sibling, in yellow, their parent, in gray, and the other siblings and parents along the path back to the root. Another user can compute the relevant hashes at each level in the tree, then compare the resulting Merkle root to the one stored in the blockchain. These “Merkle proofs” are the foundation of Bitcoin’s simplified payment verification (SPV) clients, and also several of Ethereum’s scaling proposals.
Ethereum uses three separate Merkle trees to record the data in each block: one for the block’s transactions; a second for a set of “receipts” for those transactions, which represent each transaction’s effects; and a third for recording the instantaneous state of all accounts, including their balances and associated data. Storing the entire state of the system with every block sounds tremendously wasteful, but since each block modifies only a very small subset of leaf nodes, most branches of the state tree do not change from block to block, and each new state tree can refer to entire branches of the previous one with minimal overhead. There are a few technical complications with this approach, and for that reason Ethereum actually uses a slightly different data structure called a Merkle-Patricia tree, but the concept is the same.
Ethereum’s Fast-Sync Nodes
The most important fact in all of this is that the properties of cryptographic hash functions ensure that it is practically impossible to construct two different trees with the same root. As a result, the record of Merkle roots stored in Ethereum’s block headers is sufficient to establish that the network at the time validated the corresponding transactions and state transitions.
In other words, even after a node has “forgotten” the contents of old blocks, as long as it keeps the (much smaller) block headers in storage, it can query a full node for a given block’s contents and verify for itself that the full node has not tampered with any data. It does this simply by recomputing the relevant Merkle roots and comparing to the corresponding values in the block’s header. (Note that here and for the remainder of the article, I’ve switched back to using “node” to refer to a peer on the network, not an item in a Merkle tree.)
This approach is exactly how the Go Ethereum (geth) wallet’s fast-sync option works. To perform a fast-sync, a new node first downloads and verifies all block headers, starting with the genesis block (actually, only every 100th block header must be verified; see the GitHub link for details). Since the headers contain the proof-of-work, this step is sufficient to show that the network came to consensus about the Merkle roots in each header at the time the block was mined.
At some point in the recent past, say, 1024 blocks ago, the node gets a full version of the state tree from its peers and validates it against the Merkle root in the corresponding header. From that point forward, the node downloads full blocks from peers and replays all transactions until it has reached the most recent block, at which point it simply turns into an ordinary full node.
Although Go Ethereum does not currently support it, it is also possible for nodes to continuously prune the state tree as time progresses, keeping the amount of state data that must be stored to a minimum.
Child Chain Pruning on Ardor
If you have studied Ardor’s parent-chain/child-chain architecture, this strategy hopefully sounds quite familiar. Ardor takes a very similar approach with regards to its child chains.
Briefly, the Ardor platform consists of a single proof-of-stake parent chain, also called Ardor, and a set of child chains. The parent chain supports only a few transaction types, basically, just those required for transferring ARDR around and for forging with it. The child chains, in turn, handle all of the actual business conducted on the platform using the smart transactions I described in the previous article in this series.
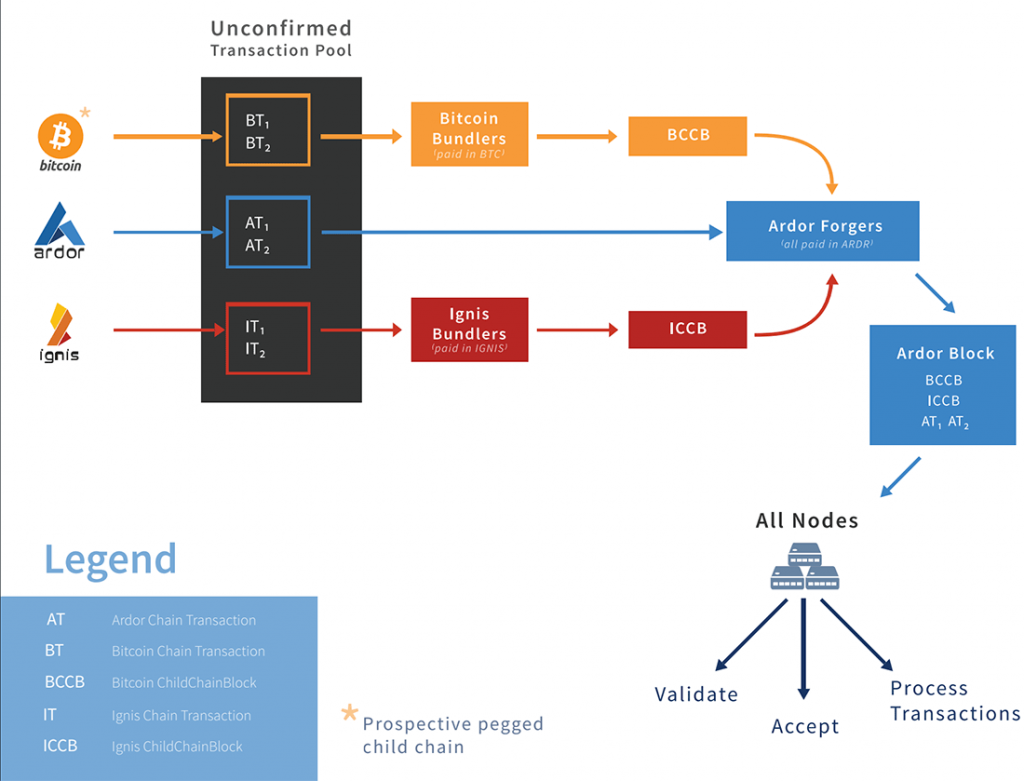
Only the parent chain’s coin (ARDR) can be used to forge. Transactions involving only the child chains’ coins do not affect the balances of the forging coin, so they are not essential to the security of the blockchain and do not need to be stored permanently. Special “bundler” nodes on each child chain collect these transactions, group them together, hash them, and report the hash to the network using a special transaction type called ChildChainBlock. They include the full transaction data along with each ChildChainBlock transaction, so forgers and other nodes can verify that the child-chain transactions are valid and do indeed produce the reported hash, but the transaction data itself is not stored in the blockchain, and after a specified time passes it can be pruned away. All that remains in the parent blockchain is the hash of this data.
Optionally, special archival nodes on each child chain can store the full history of that child chain’s transactions. In cases where this history is needed, nodes can retrieve it, hash the original bundles of transactions, and verify that the hashes match the ones recorded on the blockchain.
Hopefully, the comparison to geth’s fast-sync option is clear at this point: in both cases, nodes do not need to store the vast majority of transaction data to be able to verify that the network approved of those transactions at the time they were made. On Ethereum, it is sufficient to verify the proof-of-work in the block headers and the accuracy of any given Merkle root to be able to trust the corresponding state tree. Ardor is slightly more complicated because it uses proof-of-stake for consensus, but storing the full record of ARDR transactions along with ChildChainBlock transactions ensures that nodes can verify, starting from the genesis block, that each block was forged by an eligible forger.
Comparing the Two Designs

At this point, I hope you agree with me that we can draw the following parallels between Ethereum and Ardor:
- An Ethereum full node is similar to an Ardor node that also stores the full history of every child chain.
- An Ethereum fast-sync node that continuously prunes the state tree is similar to an ordinary Ardor node, which stores the full parent chain but prunes away all child-chain data.
- Ardor offers the ability to run a node that stores the entire parent blockchain, plus the archived transaction data for a single child chain. This option currently has no equivalent on Ethereum.
These analogies are not perfect, of course. Specifically, it is worth noting that Ethereum’s block headers are considerably smaller than full parent chain blocks on Ardor. I’ve also glossed over the mechanism that Ardor uses to track snapshots of the full state of the system and store hashes of those snapshots in the parent chain.
Still, I think this comparison is helpful. The third item in this list is especially interesting since it seems to be the biggest qualitative difference between the two designs. On Ardor, the ability to store each child chain’s transaction history in a separate set of archival nodes allows for a type of vertical partitioning of the blockchain database. Since each child chain likely supports a different business or project, partitioning the total set of all transactions along the lines defined by child chains seems like a natural choice. On Ethereum, perhaps the best analogy would be a design where a user could run a full node for a single project, like Golem, without having to simultaneously run full nodes for Augur and BAT and hundreds of other projects.
On that note, it strikes me that Ethereum’s Merkle trees might naturally accommodate such a design, where a “Golem full node” would search the full blockchain for all transactions involving GNT, store Merkle proofs for those transactions and state transitions permanently, and discard the remaining data. I admit I haven’t thought through the implications of this idea, though, so I won’t say much more about it here.
In any event, neither this hypothetical strategy for Ethereum, nor Ardor’s parent-chain/child-chain architecture, represents true sharding of the blockchain, since in both cases each node still must process all transactions from the whole network. These designs partition the storage, but not the bandwidth or computational power, required to run the blockchain. A proper scaling strategy must address all three bottlenecks.
Speaking of sharding…
Sharding
Ethereum’s long-term vision for on-chain scaling is sharding, a way of partitioning both the storage of data and the processing of transactions. The goal is for most nodes on the network to have to process transactions from only a single shard, freeing them from the burden of validating and storing transactions that affect only other shards.
I won’t even attempt to survey the Ethereum team’s proposals here, as this article is already getting long, but if you’re interested in this topic I strongly recommend their fantastic sharding FAQ on GitHub.
The reason I bring up sharding, though, is that Ardor’s developers have suggested that they are exploring ways to push child-chain transaction processing to dedicated subnets of the Ardor network. They have not offered technical details yet, and I’ll refrain from speculating here about how it might work, but to me, the idea certainly seems plausible.
If the devs can deliver on this idea, then the Ardor platform will look a lot like the “basic design of a sharded blockchain” described in the Ethereum team’s document. That section of the paper describes a set of “collator” (bundler) nodes charged with collecting (bundling) transactions from a single shard (child chain), validating them, and recording their hash in a “collation header” (ChildChainBlock transaction) on the main (parent) blockchain. “Super-full nodes” (current parent-chain nodes) would process all transactions from all shards; “top-level nodes” (future parent-chain nodes) would process only the main chain blocks, but not the full contents of all collations; and “single-shard nodes” (future child-chain nodes) would process all transactions on the main chain and a single shard.
Almost all of the complications arise from cross-shard communication, and as a result, this design works best when the shards are largely independent. As I mentioned above, Ardor’s child chains might naturally accomplish this kind of partitioning, with each chain supporting a separate project, where interactions between projects are allowed but still less common than transactions within a project.
Conclusion

At this early stage, these ideas are quite tentative, of course. But the possibilities are exciting nonetheless. Ardor’s design already incorporates proof-of-stake consensus, a separate goal that the Ethereum team has set for itself, and a reasonable partitioning of the blockchain’s data, which is an obvious requirement for any sharded solution. Notably absent in Ardor are Merkle proofs, or some other compact way for partitions to trustlessly communicate state information to one another, but it does seem like these features could be built into the platform via a hard fork. The snapshot hashes and child-chain block hashes that would become Merkle roots are already present in the protocol, after all.
But what can we say about the current state of the two projects? Perhaps the most interesting fact I learned in researching and writing this article is that Ethereum actually scales far better than I had originally thought. Go Ethereum’s fast-sync option for full nodes affords some of the same advantages of Ardor’s design, and if it eventually incorporates state-tree pruning the analogy will be even closer.
On the other hand, the main drawback of Ethereum’s current design is that there must still be full nodes somewhere on the network, and those nodes must store all 300+ GB of the Ethereum blockchain. As it continues to grow, and the cost of running a full node grows along with it, one would expect the proportion of full nodes relative to fast-sync and light nodes to naturally decline. As a consequence, each full node will likely end up handling an increasing volume of requests from other nodes, further increasing the cost (in terms of bandwidth and computational power) of running a full node.
Even without sharding, Ardor’s design mitigates this potential problem by breaking Ethereum’s monolithic full nodes into sets of archival nodes that each store the current state of only one child chain. It will be possible to store the histories of several child chains simultaneously, if desired, but few nodes, or potentially none at all, will be required to store the full history of the entire system.
Needless to say, scaling a blockchain is a hard problem. Out of the several projects that I have surveyed for this series, Ardor and Ethereum seem to me to offer the most compelling visions for on-chain scaling. And while I am hopeful that both will succeed, I must admit that, judging solely from the concrete progress that each project has already made towards achieving its vision, Ardor seems to me to have an ever-so-slight head start.
About the latest Ardor testnet version

